
My binary vector search is better than your FP32 vectors
Binary Vector Search: The 30x Memory Reduction Revolution with Preserved Accuracy


Within the field of vector search, an intriguing development has arisen: binary vector search. This approach shows promise in tackling the long-standing issue of memory consumption by achieving a remarkable 30x reduction. However, a critical aspect that sparks debate is its effect on accuracy.
We believe that using binary vector search, along with specific optimization techniques, can maintain similar accuracy. To provide clarity on this subject, we showcase a series of experiments that will demonstrate the effects and implications of this approach.
What is a binary vector?
A binary vector is a representation of a vector where each element in the vector is encoded as a binary value, typically either 0 or 1. This encoding scheme transforms the original vector, which may contain real-valued or high-dimensional data, into a binary format.
$$V[1\times 256]=\left[ \begin{matrix} -0.021 & 0.243 & 0.065 & -0.223 & \cdots & 0.452 & -0.248 \end{matrix} \right]$$
$$BV[1\times 256]=\left[ \begin{matrix} 0 & 1 & 1 & 0 & \cdots & 1 & 0 \end{matrix} \right]$$
Binary vectors require only one bit of memory to store each element, while the original float32 vectors need 4 bytes for each element. This means that using binary vectors can reduce memory usage by up to 32 times. Additionally, this reduction in memory requirements corresponds to a notable increase in Requests Per Second (RPS) for binary vector operations.
Let's consider an example where we have 1 million vectors, and each vector is represented by float32 values in a 3072-dimensional space. In this scenario, the original float32 vector index would require around 20 gigabytes (GB) of memory to store all the vectors.
Now, if we were to use binary vectors instead, the memory usage would be significantly reduced. In this case, the binary vector index would take approximately 600 megabytes (MB) to store all 1 million vectors.

However, it was expected that this reduction in memory would lead to a significant decrease in accuracy because binary vectors lose a lot of the original information.
Surprisingly, our experiments showed that the decrease in accuracy was not as big as expected. Even though binary vectors lose some specific details, they can still capture important patterns and similarities that allow them to maintain a reasonable level of accuracy.
Experiment
To evaluate the performance metrics in comparison to the original vector approach, we conducted benchmarking using the dbpedia-entities-openai3-text-embedding-3-large-3072-1M dataset. The benchmark was performed on a Google Cloud virtual machine (VM) with specifications of n2-standard-8, which includes 8 virtual CPUs and 32GB of memory. We used pgvecto.rs v0.2.1 as the vector database.
After inserting 1 million vectors into the database table, we built indexes for both the original float32 vectors and the binary vectors.
CREATE TABLE openai3072 (
id bigserial PRIMARY KEY,
text_embedding_3_large_3072_embedding vector(3072),
text_embedding_3_large_3072_bvector bvector(3072)
);
CREATE INDEX openai_vector_index on openai3072 using vectors(text_embedding_3_large_3072_embedding vector_l2_ops);
CREATE INDEX openai_vector_index_bvector ON public.openai3072 USING vectors (text_embedding_3_large_3072_bvector bvector_l2_ops);
After building the indexes, we conducted vector search queries to assess the performance. These queries were executed with varying limits, indicating the number of search results to be retrieved (limit 5, 10, 50, 100).
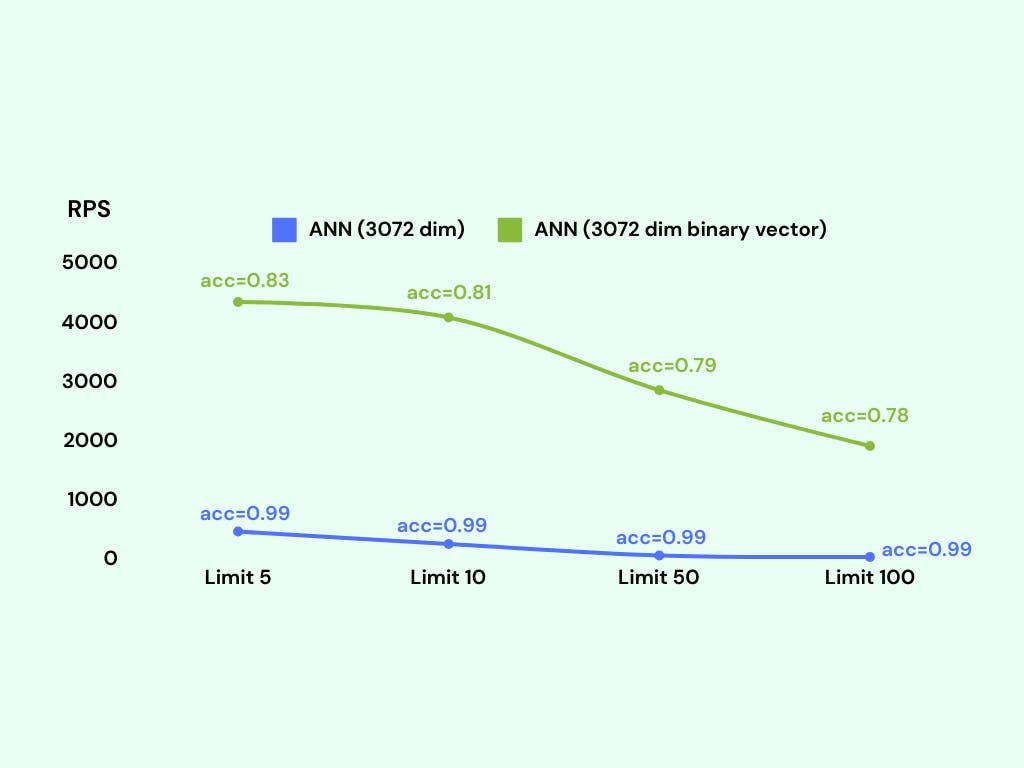
We observed that the Requests Per Second (RPS) for binary vector search was approximately 3000, whereas the RPS for the original vector search was only around 300.
The RPS metric indicates the number of requests or queries that can be processed by the system per second. A higher RPS value signifies a higher throughput and faster response time.
However, the accuracy of the binary vector search was reduced to about 80% compared to the original vector search. While this decrease may not be seen as significant in some cases, it can be considered unacceptable in certain situations where achieving high accuracy is crucial.
Optimization: adaptive retrieval
Luckily, we have a simple and effective method called adaptive retrieval, which we learned from the Matryoshka Representation Learning, to improve the accuracy.
The name is complex but the idea behind adaptive retrieval is straightforward. Let's say we want to find the best 100 candidates. We can follow these steps:
Query the binary vector index to retrieve a larger set (e.g. 200 candidates) from the 1 million embeddings. This is a fast operation.
Rerank the candidates using a KNN query to retrieve the top 100 candidates. Please notice that we are running KNN instead of ANN. KNN is well-suited for scenarios where we need to work with smaller sets and perform accurate similarity search, making it an excellent choice for reranking in this case.

By incorporating this reranking step, we can achieve a notable increase in accuracy, potentially reaching up to 95%. Additionally, the system maintains a high Requests Per Second (RPS), approximately 1700. Furthermore, despite these improvements, the memory usage of the index remains significantly smaller, around 30 times less, compared to the original vector representation.

Below is the SQL code that can be used to execute the adaptive retrieval:
CREATE OR REPLACE FUNCTION match_documents_adaptive(
query_embedding vector(3072),
match_count int
)
RETURNS SETOF openai3072
LANGUAGE SQL
AS $$
-- Step 1: Query binary vector index to retrieve match_count * 2 candidates
WITH shortlist AS (
SELECT *
FROM openai3072
ORDER BY text_embedding_3_large_3072_bvector <-> binarize(query_embedding)
LIMIT match_count * 2
)
-- Step 2: Rerank the candidates using a KNN query to retrieve the top candidates
SELECT *
FROM shortlist
ORDER BY text_embedding_3_large_3072_embedding <-> query_embedding
LIMIT match_count;
$$;
Comparison with shortening vectors
OpenAI latest embedding model text-embedding-3-large has a feature that allows you to shorten vectors.

It produces embeddings with 3072 dimensions by default. But you could safely remove some numbers from the end of the sequence and still maintain a valid representation for the text. For example, you could shorten the embeddings to 1024 dimensions.
This feature can help you save memory and make your requests faster, just like binary vectors. It would be a good idea to compare the performance and see which one works better for your needs.
Based on what we discovered, the conclusion is clear: Binary vectors significantly outperform shortened vectors.
We performed similar benchmarks to compare with binary vectors. We created indexes using the same dataset and machine type, but with varying dimensionalities. One index had 256 dimensions, while the other had 1024 dimensions.

The 1024-dimensional index achieved an accuracy of approximately 85% with a request rate of 1000 requests per second (RPS). On the other hand, the 256-dimensional index had around 60% accuracy with a higher request rate of 1200 RPS.
The 1024-dimensional index required approximately 8GB of memory, while the 256-dimensional index used around 2GB. In comparison, the binary vector approach achieved an accuracy of around 80% with a request rate of 3000 RPS, and its memory usage was approximately 600MB.

We implemented adaptive retrieval with lower-dimensional indexes. The binary vector index still outperformed the 256-dimensional index in terms of both request rate (RPS) and accuracy, while also exhibiting lower memory usage. On the other hand, the adaptive retrieval with the 1024-dimensional index achieved a higher accuracy of 99%; however, it had a relatively lower request rate and consumed 12 times more memory compared to the other indexes.

Summary
By utilizing adaptive retrieval techniques, binary vectors can maintain a high level of accuracy while significantly reducing memory usage by 30 times. We have presented benchmark metrics in a table to showcase the results. It is important to note that these outcomes are specific to the openai text-embedding-3-large model, which possesses this particular property.
