


Table of contents
We are excited to announce the release of pgvecto.rs 0.2, a significant milestone in the journey of bridging the gap between relational queries and vector search in PostgreSQL. This update brings together the power of both worlds, offering enhanced efficiency and enabling complex queries within PostgreSQL.
In the past, developers and data scientists encountered the significant challenge of managing separate systems for relational queries and vector search. This resulted in increased complexity and resource overhead. However, with the release of pgvecto.rs 0.2, we have addressed this issue by integrating the cutting-edge VBASE method from OSDI 2023. This integration has substantially refined the efficiency of vector search within PostgreSQL.
Real-world applications: Immich
Real-world applications often require complex queries that go beyond simple Approximate Nearest Neighbor (ANN) search. To explore a practical example of such applications, let's take a closer look at immich, a self-hosted photo and video backup solution that highlights the importance of advanced vector and traditional relational queries.

immich leverages advanced vector-based and relational queries to provide intelligent search capabilities. With immich, you can efficiently search and discover relevant media files based on visual similarity, metadata, and user-defined tags. The underlying technology powering this functionality is pgvecto.rs.
We will provide a concise overview of the search feature in immich. Consider a scenario where our database consists of three tables.
CREATE TABLE AssetEntity (
id UUID PRIMARY KEY,
ownerId VARCHAR NOT NULL,
createdAt TIMESTAMPTZ NOT NULL,
updatedAt TIMESTAMPTZ NOT NULL,
deletedAt TIMESTAMPTZ,
isArchived BOOLEAN DEFAULT false,
isVisible BOOLEAN DEFAULT true,
...
);
CREATE TABLE ExifInfo (
id INT PRIMARY KEY,
assetId UUID,
lat FLOAT,
long FLOAT,
city VARCHAR(255),
state VARCHAR(255),
country VARCHAR(255),
description TEXT,
...
);
CREATE TABLE ImageEmbedding (
id INT PRIMARY KEY,
assetId UUID,
embedding vector(n), -- assuming 'n' is the dimensionality of the vector
...
);
We have a table named AssetEntity that stores information about the images, including their unique identifier (id), the owner (ownerId), creation and update timestamps (createdAt and updatedAt), and other relevant attributes.
The ExifInfo table contains information specific to the EXIF data of the images, such as the latitude (lat), longitude (long), city, state, country, and description. The assetId column in this table establishes a relationship with the asset_entity table.
Additionally, we have the ImageEmbedding table, which stores vector-based embeddings for each image. The embedding column is an array of floating-point numbers representing the image embedding vector. The assetId column in this table also establishes a relationship with the asset_entity table.
The query statement below is used to search for images based on certain criteria and sorting by the similarity of the image embeddings. It joins the AssetEntity, ImageEmbedding, and ExifInfo tables, filters the results based on criteria like ownerId, isArchived, isVisible, createdAt, and city in the EXIF info, then orders the images by the similarity of the provided embedding. The query returns a limited number of results based on the specified limit.
SELECT a.*, e.*, e.*
FROM AssetEntity AS a
INNER JOIN ImageEmbedding AS e ON e.assetId = a.id
LEFT JOIN ExifInfo AS e ON e.assetId = a.id
WHERE a.ownerId IN (:userIds)
AND a.isArchived = false
AND a.isVisible = true
AND a.createdAt < NOW()
AND e.city = :city
ORDER BY s.embedding <=> :embedding
LIMIT :numResults;
It can be seen as a scenario involving Single-Vector TopK + Filter + Join operations. The limitations of pgvector in supporting such operations highlight the need for VBASE.
When it comes to Single-Vector TopK operations, pgvector falls short in providing efficient performance. TopK queries require finding the K nearest neighbors to a target vector, but pgvector struggles to predict the optimal value of K, leading to suboptimal query performance. VBASE, on the other hand, addresses this limitation by leveraging relaxed monotonicity and offering significantly higher efficiency. It provides a more accurate and efficient solution for single-vector TopK queries.
Additionally, pgvector's support for Filter and Join operations in conjunction with vector queries is limited. Complex queries that involve filtering or joining on both scalar and vector data can be challenging to execute efficiently in pgvector. VBASE, however, is designed to handle these types of queries seamlessly. It integrates vector search systems with relational databases, allowing for the execution of complex queries involving filters and joins on both scalar and vector attributes. This capability makes VBASE a more suitable choice for applications that require these operations.
Benchmark
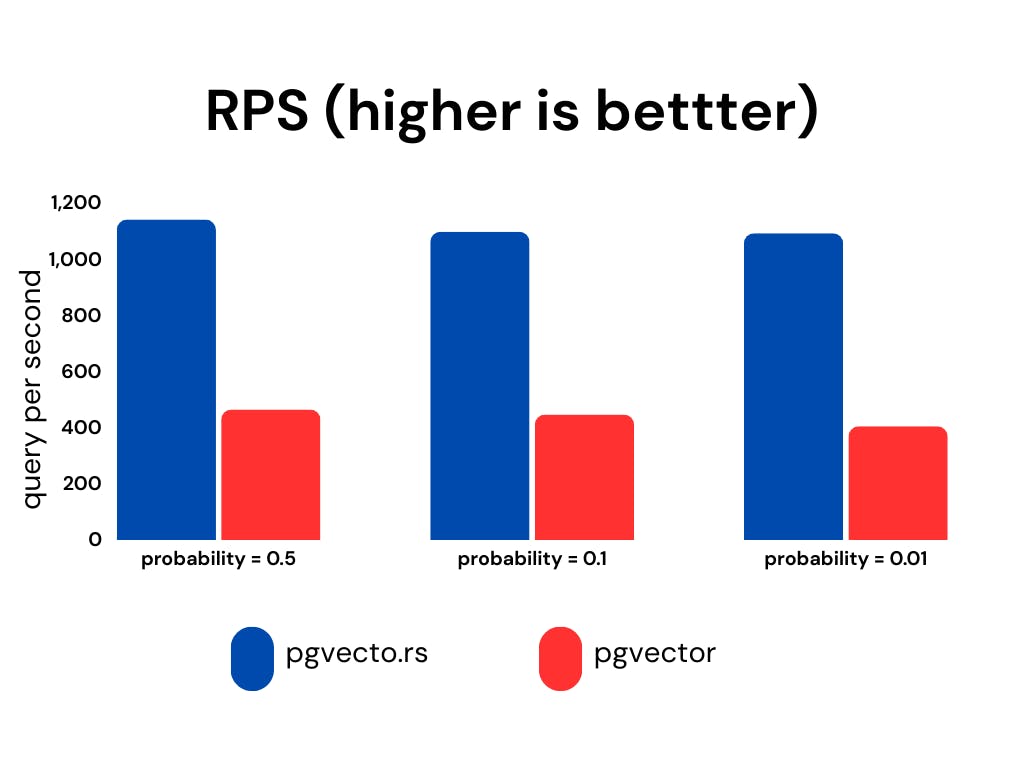
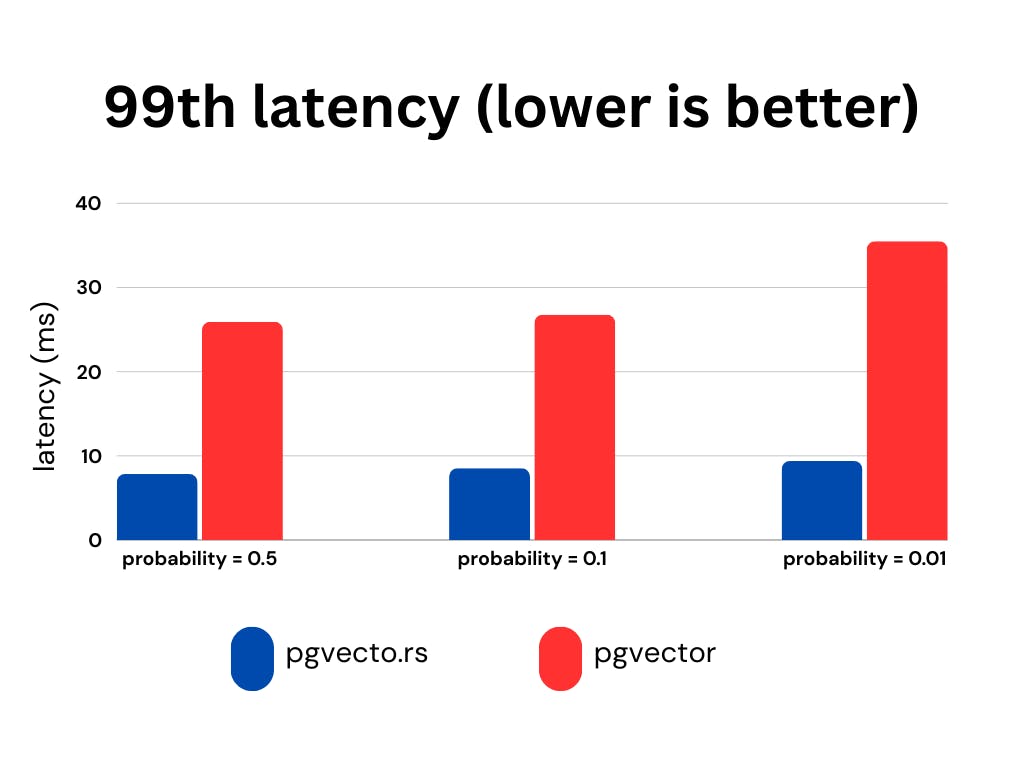
To evaluate the performance, benchmarks can be conducted to measure the efficiency and effectiveness of both systems. We utilize the laion-768-5m-ip-probability dataset for benchmarking purposes due to the absence of a comprehensive relational benchmark. The dataset is derived from LAION 2B images. It contains 5,000,000 vectors, 10,000 queries.
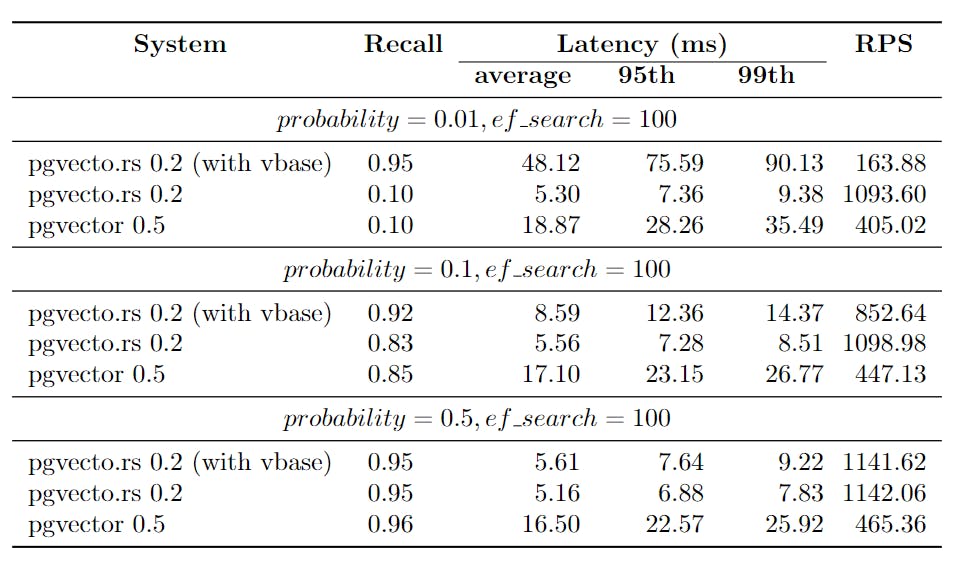
The dataset includes a probability column that stores random floating-point values generated from a uniform distribution between 0 and 1. The ratio of 0.01 means that each query covers 1% (or 0.01 times) of the dataset, allowing for focused analysis.
We present the recall, latency (in milliseconds), and RPS (requests per second) for various probability ranges while keeping the ef_search constant. The ef_search parameter represents the size of the list utilized during k-NN (k-Nearest Neighbors) searches, determining the trade-off between search accuracy and query processing time.
pgvecto.rs, when used with VBASE, consistently yields improved recall, particularly when working with low probability values.
Other features
pgvecto.rs 0.2 introduces the following key features and improvements other than VBASE integration:
FP16: Users can now store embeddings in PostgreSQL using half the float32 size, significantly improving latency. This optimization has a negligible impact on final recall, less than 1%.
Asynchronous indexing: Insertion operations are non-blocking, ensuring a smoother and more efficient data insertion and indexing process.
Doubled query performance: pgvecto.rs 0.2 offers query performance that is twice as fast as the previous version (0.1), marking a significant leap forward in system efficiency.
Observability: The new
pg_vector_index_statview provides a transparent view into the indexing internals of pgvecto.rs. Users can monitor index construction, configuration adjustments, and detailed statistical analysis in real time, fostering a more intuitive and controlled environment.
Quick start
To get started with pgvecto.rs 0.2, you could run it in a docker container:
docker run \
--name pgvecto-rs-demo \
-e POSTGRES_PASSWORD=mysecretpassword \
-p 5432:5432 \
-d tensorchord/pgvecto-rs:pg16-v0.2.0
Please check out our documentation for more details. We encourage you to try out pgvecto.rs, benchmark it against your workloads, and contribute your indexing innovations. Join our Discord community to connect with the developers and other users working to improve pgvecto.rs!